



 Live Chat
Live Chat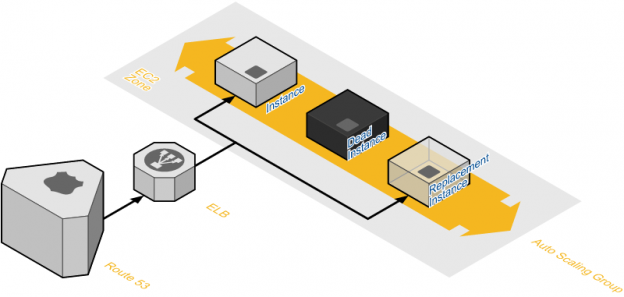
The concept of Auto scaling, since its evolution, has been a major selling point in the field of ‘cloud computing’. But as compared to most of the popularized technological abilities, a fair cluster of some misconceptions has been collected.
There are few kinds of mistakes which slides in the passage of various constructive conversations regarding cloud infrastructure, and then they frequently mislead various IT leaders taking the belief into consideration that it is very quick for its set up, is simple and confirms ‘100% uptime’.
1. ‘Auto-scaling’ is pretty easy
It becomes pretty possible with the platforms of IaaS, generally in a manner which is quite direct as compared for scaling upward in some data-center. But if customer are visiting AWS and spinning up any instance, then you will rapidly discover regarding public cloud, which never “comes with” with the concept of auto scaling.
For designing an automatic and a self-healing ecosystem that takes the place of various failed up instances and then usually comes out with almost no or little human intervention which needs a noteworthy ‘time-investment upfront’. The process of setting up of a group of load balancing in between various ‘Availability Zones’ (AZs) is almost some-what very direct; designing instances on its own with a systematic and precise configuration along with least standup times in a need of various customized scripts and various templates that basically process weeks or may be months for getting right, and which generally does not possess the time duration which is taken for the engineers for learning how effectively AWS’ tools can be used.
At Go4hosting, the process of auto scaling generally possess three major components:
•The process of cloud formation might be utilized for making a template of configuration of the resources and application, which is basically structured as a data stack. This specific template be successfully carried in a concerned repository, thus making it deployable and easily reproducible as instances, where and when it is required. Also, cloud formation enables customers for automating various things like network infrastructure, deploying secure and ‘multi-AZ instances’, in fact can download bundles of various acute tasks which are pretty much time-taking if they are done manual manner.
• “Amazon-Machine-Images”: Under the process of auto scaling, like under a very traditional environment, various machine images enables the engineers for spinning up same replicas of already existing machines. An AMI, basically is utilized for designing a ‘virtual machine’ under an EC2 and which offers as the fundamental deployment unit. The concerned degree for which the idea of AMI must be precisely customized as compared to configuring a startup is basically a complicated topic.
• “Puppet scripts,” along with various management configuring tools such as Chef, which defines each and everything over the suitable servers from given single location, such that there is an individual truth regarding state of complete architecture. Cloud formation designs the foundational unit and thus installs the configuration of Puppet master, after it, Puppet which is attached towards the various resources, thus node needs to function such as extra block storage, Elastic IPs and network interfaces. A last step is basically the integration of auto scaling and the deployed process, where ‘Puppet scripts’ updates EC2 instances which are newly added on its own towards groups of auto scaling.
Managing various templates and various scripts which are added in the process of auto-scaling is basically ‘no mean feat’. It might take time for an expert systems engineer for getting easy working with ‘JSON’ in ‘CloudFormation’. This moment is precisely the time when acute engineering teams generally do not possess, and that is why various teams are not able to touch the exact point of exact auto-scaling, relying not on some concerned combination of manual configuration and ‘elastic load balancing’. Allocating various type of external or internal resources for creating ‘template-driven environments’ can minimize customers’ build out time by various specific orders of concerned magnitude. That is the reason why several IT firms have devoted a complete team of experienced engineers for managing automation scripts, generally referred a ‘DevOps team’.

2. ‘Elastic-scaling’ is comparatively more often than ‘fixed-size’ auto-scaling
The story of Auto scaling not always applies the concept of ‘load-based scaling’. In fact, this is pretty much argue able that the major helpful aspect of the idea of ‘auto- scaling’ focuses on great range of availability along with the redundancy, and instead of any ‘elastic-scaling’ techniques.
Very frequent objective for such a cluster is basically resiliency; various instances are situated into a non-flexible size of auto-scaling cluster so that by chance if any an instance is failing, then it is replaced on its own. The use case is an ‘auto-scaling’ cluster which has a minimum size of ‘1’.
In addition to this, there are plenty of ways for scaling a group than simply by assuming at ‘CPU load’. The process of auto scaling may also sum up capacity towards working queues, and thus is very helpful in projects of data analytic. A suitable group of ‘worker-servers’ in a group of auto scaling basically listens towards a queue, then implement those actions, then timely trigger an instance of spot when the concerned size of queue reaches a specific number. Similar to all other instances, this is only going to occur if and only if the price of spot instance falls under a specific dollar amount. By this manner, capacity is included when that is only “good to possess”.
3. The capacity must always match specific demand
There is a general misconception regarding “load-based auto-scaling” is such that this is pretty much suitable in all kinds of environment.
And in fact, there are various cloud computing and deployments models which are more resilient and with not any function of process of auto scaling. This becomes especially very true of acute startups that possess actually lesser than ‘50 instances’, and where such desirable ‘closely-matching’ capacity along with the demand which has various unexpected consequences.
For example there is a startup which possess a ‘traffic peak’ at ‘5:00PM’. That particular traffic peak needs 12’ ‘EC2 instances’, but can receive with only two “EC2 instances”. It is decided that for saving costs and thus taking usefulness of their particular cloud’s ‘auto-scaling’ ability, they will putting up their various instances under a group of auto scaling with a ‘maximal size of fifteen’ and a ‘minimal size of two’.
Although, one fine day they receive a massive height of concerned traffic around about ‘10:00AM’ that is great as ‘5:00PM’ traffic — which basically lasts only for fixed 3 minutes.
So, why does that particular website goes down even if they possess ‘auto-scaling’? There exist various quantity of factors. Firstly, their group of auto scaling will only sum up instances in every 5 minutes just by some default, and this may also consume ‘3-5 minutes’ for some new instance for coming in service. To obvious, their additional capacity can be quite late for meeting “10:00AM” spike.
In general, it is usually true that the concept of “auto-scaling” is very beneficial for the people that are manually scaling for ‘hundreds of servers’ and not towards tons of various servers. If users are letting their capacity go down under a specific quantity, users are possibly quite susceptible for the downtime. Does not matter how those group of auto scaling is basically setting up, that still consumes somewhat ‘5 minutes’ for any instance for brought up; in just 5 minutes, plenty of traffic can be generated, and in only 10 minutes a website can be saturated. This is the reason why ‘90% of scale down’ is a pretty much. Under the afore-mentioned example, startup must try for scaling the peak 20% of the concerned amount.
4. ‘Perfect base images’ > ‘lengthy configurations’
This is generally quite difficult for finding out the significant balance in between getting baked towards the AMI (for creating “Golden Master”), then what is being done by launching with a management configuring tool (on peak of “Vanilla AMI”). The way customer is configuring an instance is based on how quick the instance requires for spinning up, how commonly events occur, the aggregate life of any instance.
The usefulness of utilizing a management configuring tool and then creating off of a ‘Vanilla AMIs’ is obvious: suppose the customer is executing 100+ machines, he/she can update various packages in an individual place and thus bearing a track record of each and every configuring change. We have discussed the merits of ‘configuration management’ in an extended manner here.
Although, in an event of auto scaling, you generally do not wish to bear for waiting up for a Puppet or various script for getting downloaded and then installing 500MB of relevant packages. Moreover, the by default process of installation must execute, the greater the chance will occur that something is going to be wrong.
With the phase of time along with testing, this is very much possible for attaining a genuine balance of such two particular approaches. It will be ideal feature for starting up from a specific stock image designed after implementing Puppet on a specific instance. This concerned test of various deployed process, basically is or maybe not, the instances operations automatically when designed from this already existing image as build up from “scratch”.
Also, setting up the process is very much complicated along with time-taking project with any experienced engineering team. There is no doubt for the next several decades, various 3rd party tools and techniques will rise for facilitating this quite process, but such tools of cloud management possess cloud adoption. Unless until tools such as ‘Amazon’s OpsWorks’ become more powerful, the influence of any various environment’s ‘auto scaling’ process will be based on the certified skills of process of various ‘cloud-automation engineers’. Go4hosting is a very genuine cloud hosting services provider which efficiently provides its clients attain hundred percent availability over Amazon Web Service and private cloud.